LZW (Lempel-Ziv-Welch) kompresia
Komprimačný algoritmus označovaný ako LZW je pomenovaný podľa svojich objaviteľov pánov A.Lempela , J.Ziva a Terryho A.Welcha, ktorý pôvodný algoritmus LZ77 modifikoval. Jedná sa o bezstratovú komprimačnú metódu vhodnú na kompresiu jak grafických tak aj bilineárnych a textových súborov. Rôzne modifikácie metódy LZW sa používajú v bežných komprimačných programov PKARC, PAK, PKZIP, v UNIX-e príkaz "compress" ako aj pri formátoch počítačovej grafiky GIF, TIFF, PostScript... Rôzne metódy tejto kompresie sú patentované firmami IBM, Unisys a Compuserve. Základným princípom kompresného algoritmu LZW je vyhľadávanie rovnakých, opakujúcich sa reťazcov v spracovávanom vstupnom súbore a priraďovať im kódy.
| Tab.1 Príklad Slovníka | |
|
kód
|
reťazce |
| 0000 | 0 |
| 0001 | 1 |
| : | : |
| 0254 | 254 |
| 0255 | 255 |
| 0256 | 145 201 4 |
| 0257 | 243 245 |
| : | : |
| 4096 | XXX XXX XXX |
Nasledujúci príklad ukazuje veľmi zjednodušene (v samotnom algoritme LZW je to zložitejšie) kompresiu pomocou slovníka (dictionary). Predpokladáme, že slovník má kapacitu 4096 položiek. Z toho vyplýva, že jednotlivé kódy budú reprezentované pomocou 12 bitov. Kódy 0-255 v slovníku sú vyhradené a predstavujú jednotlivé byty (napr. ASCII znaky) vstupného súboru. Kompresia sa dosahuje použitím kódov 256 až 4095, ktoré reprezentujú reťazce. Napr. kód 256 reprezentuje sekvenciu 3 bytov 145 201 4. Vždy keď kompresný algoritmus narazí na tento reťazec vo vstupnom súbore umiestni kód 256 do výstupného kódovaného súboru. Pri dekompresii je kód 256 preložený pomocou slovníka do pôvodnej sekvencie bytov 145 201 4. Dlhé reťazce pripadajúce jednotlivým kódom a ich častý výskyt vo vstupnom súbore vedie k vysokej kompresii.
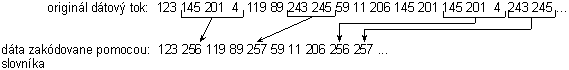
- Tento prístup je značne zjednodušený a treba nájsť odpoveď na niektoré otázky:
- ako určiť aké reťazce majú byť v slovníku
- ako odovzdať dekompresoru rovnaký slovník aký použil kompresor
Algoritmus LZW pracuje so slovníkom, ktorý sa adaptívne prispôsobuje kódovaným dátam. Táto adaptívna metóda
vytvára dynamický substitučný slovník. Slovník nieje potrebné prenášať pre potreby dekompresie, pretože dekompresor
si vie z prijímaných dát vytvoriť vlastný duplicitný slovník.
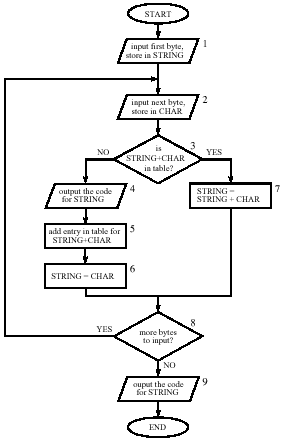
Vývojový diagram kompresného algoritmu LZW je uvedený na obrázku Obr.1.
Tabuľka Tab.2 ukazuje detailne krok za krokom funkciu
algoritmu na príklade vstupného súboru pozostávajúceho z 45 bytov ASCII textu
the/rain/in/Spain/falls/mainly/on/the/plain. Keď hovoríme, že kompresor
číta znak "a" zo vstupného súboru myslíme tím hodnotu 01100001 (číslo 97 vyjadrené
8 bitmi), kde 97 ja ASCII kód znaku "a" . Keď hovoríme, že zapíšeme znak "a"
do kódovaného (komprimovaného) súboru myslíme tým 000001100001 (97 vyjadrené
12 bitmi).
Algoritmus využíva dve premenné CHAR a STRING. Premenná CHAR je vyhradená pre jeden znak resp. môže obsahovať hodnotu v
rozsahu 0 až 255 teda 1 byte. STRING je premenná s premenlivou dĺžkou reťazca, napr. skupina jedného alebo viac znakov
s ktorého každý znak predstavuje 1 byte.
Popis kompresného algoritmu LZW
- Kompresor štartuje prijatím prvého znaku zo vstupného súboru a umiestni ho do premennej STRING.
- Ďalší znak prečítaný zo vstupného súboru je uložený do premennej CHAR.
- Slovník je prehľadávaný za účelom zistenia výskytu duplicitných reťazcov, ktorým odpovedá príslušný kód. V bloku podmienky (3) je reťazec STRING+CHAR porovnávaný s reťazcami uloženými v slovníku. Môžu nastať dva prípady:
- Reťazec sa NACHÁDZA v slovníku:
- Proces v bode 2. a 3. pokračuje pokiaľ niesu prečítané všetky znaky zo vstupného súboru (8).
- Po prečítané a spracovaní posledného znaku zo vstupného súboru program
zapíše aktuálnu hodnotu STRING do komprimovaného súboru (9) v tabuľke riadok
45.

-
Reťazec sa NENACHÁDZA v slovníku:
Nasledujú operácie (4),(5) a (6). V bloku (4) je 12 bitoví kód korešpondujúci s obsahom premennej STRING zapísaný do komprimovaného súboru. V ďalšom kroku (5) je uložený do slovníka nový reťazec STRING+CHAR a je mu priradený kód. V bloku (6) je premennej STRING predaná hodnota premennej CHAR.
Príkladom takejto akcie sú riadky 2 až 10 v tabuľke 2 pre prvých 10 znakov vstupného súboru. V riadku 2 sa do premennej CHAR uloží aktuálne prečítaný znak CHAR=h. V premennej STRING je predchádzajúci znak, ktorý bol prečítaný ako prvý STRING=t.
(1) STRING=t (prvý znak ktorý bol prečítaný zo vstupného súboru)
(2) CHAR=h (aktuálne načítaný znak zo vstupného súboru)
(3) je reťazec STRING+CHAR=th v slovníku? reťazec th nieje v slovníku
(4) zapíš kód odpovedajúci obsahu STRING=t do komprimovaného súboru
(5) pridaj reťazec th do slovníku a priraď mu kód (256=th)
(6) STRING=CHAR teda STRING=h
(2) do CHAR načítaj ďalší znak zo vstupného súboru...
Príkladom tejto akcie je riadok 11 v tabuľke 2.
STRING=i
(2) CHAR=n
(3) je reťazec STRING+CHAR=in v slovníku? áno je (v riadku 8 kód 262=in)
(7) STRING=STRING+CHAR=in
(2) CHAR=/ (riadok 12, načítame ďalší znak zo vstupného súboru do CHAR)
(3) je reťazec STRING+CHAR=in/ v slovníku? Nieje. Postup je zrejmí. Zaradíme do slovníku 265=in/
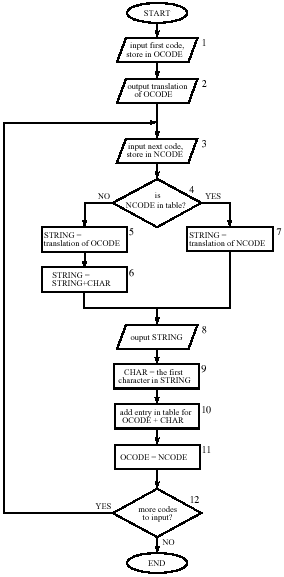
Vývojoví diagram algoritmu LZW pre dekompresiu je uvedení na Obr.1 vpravo. Každý kód prečítaný zo vstupného skomprimovaného súboru je porovnaný s obsahom slovníku, ktorý sa buduje priebežne počas dekompresie. Každý prečítaný kód je spracovaný takýmto spôsobom. Dekompresor používa premenné OCODE (oldcode - predchádzajúci kód) a NCODE (newcode - aktuálne prečítaný kód). Postup dekompresie je zrejmí z vývojového diagramu.
Tabuľka 2. Príklad kompresie LZW na texte anglickej frázy: the/rain/in/Spain/falls/mainly/on/the/plain
| CHAR |
STRING |
Je v slovníku? | Výstup | Pridaj do slovníku |
Nový STRING |
Komentár | |
| 1 | t | t | nie | t | prvý znak prečítaný - nič sa nedeje | ||
| 2 | h | th | nie | t | 256=th | h | |
| 3 | e | he | nie | h | 257=he | e | |
| 4 | / | e/ | nie | e | 258=e/ | / | |
| 5 | r | /r | nie | / | 259=/r | r | |
| 6 | a | ra | nie | r | 260=ra | a | |
| 7 | i | ai | nie | a | 261=ai | i | |
| 8 | n | in | nie | i | 262=in | n | |
| 9 | / | n/ | nie | n | 263=n/ | / | |
| 10 | i | /i | nie | / | 264=/i | i | |
| 11 | n | in | áno(262) | in | prvý opakujúci sa reťazec nájdený | ||
| 12 | / | in/ | nie | 262 | 265=in/ | / | |
| 13 | S | /S | nie | / | 266=/S | S | |
| 14 | p | Sp | nie | S | 267=Sp | p | |
| 15 | a | pa | nie | p | 268=pa | a | |
| 16 | i | ai | áno(261) | ai | našiel ai, ale ain ešte nieje v slovníku | ||
| 17 | n | ain | nie | 261 | 269=ain | n | pridaj ain do slovníku |
| 18 | / | n/ | áno(263) | n/ | |||
| 19 | f | n/f | nie | 263 | 270=n/f | f | |
| 20 | a | fa | nie | f | 271=fa | a | |
| 21 | l | al | nie | a | 272=al | l | |
| 22 | l | ll | nie | l | 273=ll | l | |
| 23 | s | ls | nie | l | 274=ls | s | |
| 24 | / | s/ | nie | s | 275=s/ | / | |
| 25 | m | /m | nie | / | 276=/m | m | |
| 26 | a | ma | nie | m | 277=ma | a | |
| 27 | i | ai | áno(261) | ai | našiel ai v slovníku | ||
| 28 | n | ain | áno(269) | ain | našiel aj dlší reťazec vyskytujúci sa v slovníku, ain | ||
| 29 | l | ainl | nie | 269 | 278=ainl | l | |
| 30 | y | ly | nie | l | 279=ly | y | |
| 31 | / | y/ | nie | y | 280=y/ | / | |
| 32 | o | /o | nie | / | 281=/o | o | |
| 33 | n | on | nie | o | 282=on | n | |
| 34 | / | n/ | áno(263) | n/ | |||
| 35 | t | n/t | nie | 263 | 283=n/t | t | |
| 36 | h | th | áno(256) | th | našiel th, ale the ešte nieje v slovníku | ||
| 37 | e | the | nie | 256 | 284=the | e | pridaj the do slovníku |
| 38 | / | e/ | áno(258) | e/ | |||
| 39 | p | e/p | nie | 258 | 285=e/p | p | |
| 40 | l | pl | nie | p | 286=pl | l | |
| 41 | a | la | nie | l | 87=la | a | |
| 42 | i | ai | áno(261) | ai | našiel ai v slovníku | ||
| 43 | n | ain | áno(269) | ain | našiel aj dlší reťazec vyskytujúci sa v slovníku, ain | ||
| 44 | / | ain/ | nie | 269 | 288=ain/ | / | |
| 45 | EOF | / | / | end of file, výstup STRING |
|
KOMPRESOR LZW
|
DEKOMPRESOR LZW
|
 |
 |
Na prvý pohľad by sa mohlo zdať, že realizácia algoritmu LZW by nemala činiť žiadne problémy. Avšak necitlivý prístup k implementácie algoritmu môže viesť k veľkým pamäťovým nárokom a pomalému vykonávaniu kompresie. Komerčné programy používajú rôzne triky a postupy ktorými dosahujú lepší výkon.
- Zopár problémov s ktorými sa treba vysporiadať:
-
- problém s pamäťou vzniká pretože vopred nevieme, aký dlhý bude reťazec prislúchajúci jednotlivým kódom (napr. 261=ai , 278=ainl)
- doba kompresie je limitovaná časom potrebným na vyhľadanie reťazca v slovníku
- treba zabezpečiť efektívnu správu a organizáciu slovníku
Ako analógia môže poslúžiť telefónny zoznam. Chceme nájsť v telefónnom zozname tel. číslo kamaráta a jediné čo máme je telefónny zoznam usporiadaný podľa telefónnych čísel a nie v abecednom poradí. Toto si vyžaduje prehľadávať stránku po stránke. Toto je rovnako nevýhodná situácia ako hľadať kód spomedzi 4096 kódov prislúchajúci danému reťazcu. Treba slovník zorganizovať tak, že pri hľadaný nám napovie kde máme začať hľadať resp. nepristupovať k 4096 položkám v pamäti sekvenčne, ale slovník v pamäti rozdeliť na základe nejakých pravidiel do sekcií podľa vkladaných reťazcov.
Niektoré výhody LZW kompresie:
- jednoduchá a ľahká implementácia
- rýchla kompresia a dekompresia (vhodné pri aplikáciách kritickým z hľadiska času)
- nenáročnosť na pamäť
- možnosť kontinuálneho vysielania skomprimovaných dát napr. modemom bez nutnosti čakať na dokončenie komprimácie dátového bloku
Informačné zdroje
[1] Mark Nelson, "LZW Data Compression", October 1989
http://www.dogma.net/markn/articles/lzw/lzw.htm
[2] Dominik Szopa, "The Lossless Compression (Squeeze) Page"
http://www.cs.sfu.ca/cs/CC/365/li/squeeze/